for i in range(1,101): url = 'http://nt.lianjia.com/ershoufang/pg'+str(i)+"/" res = requests.get(url=url,headers=headers) html = res.text time.sleep(0.7) lj = BeautifulSoup(html,'html.parser')
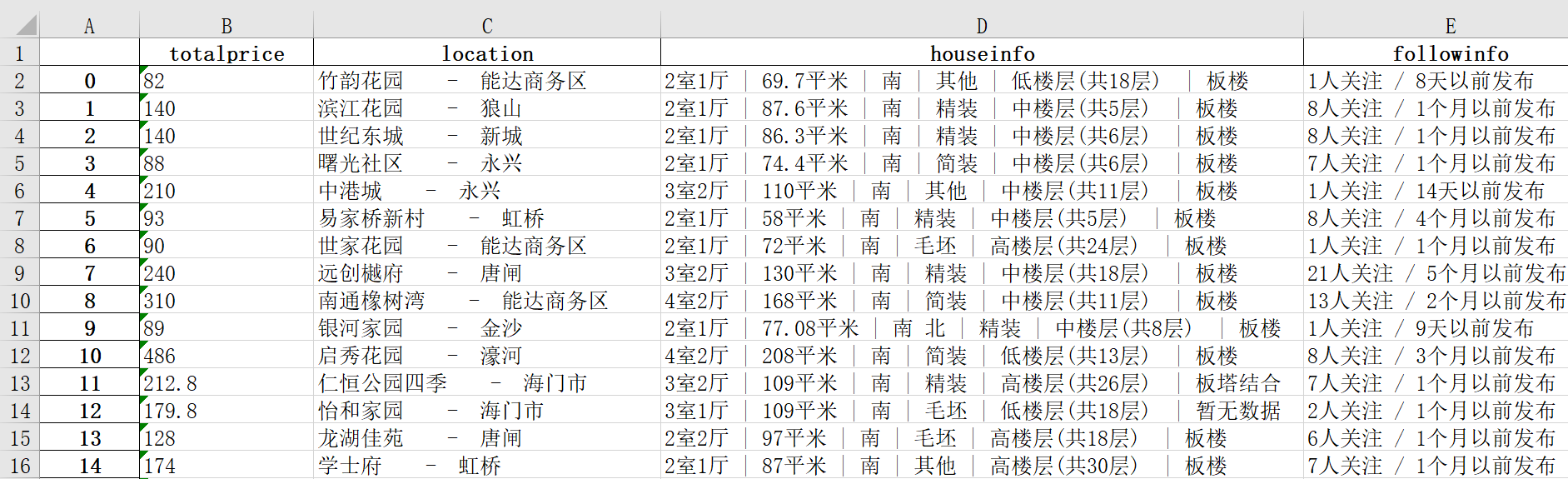
#提取价格信息 price = lj.find_all("div",attrs={"class":"priceInfo"}) for p in price: totalPrice = p.span.string tpc.append(totalPrice) #提取位置信息 price = lj.find_all("div",attrs={"class":"positionInfo"}) for l in price: location = l.get_text() loc.append(location) #提取房源信息 houseInfo = lj.find_all("div",attrs={"class":"houseInfo"}) for h in houseInfo: house = h.get_text() hio.append(house) #提取关注度信息 followInfo = lj.find_all("div",attrs={"class":"followInfo"}) for f in followInfo: follow = f.get_text() fio.append(follow)
第五步,将数据传入pandas数据框,并将其导出为Excel文件。
1 2
house = pd.DataFrame({"totalprice":tpc,"location":loc,"houseinfo":hio,"followinfo":fio}) house.to_excel("RawData.xlsx")